【IT168 评论】本节尝试独立于机器学习算法, 单纯地来讲梯度下降算法 [Gradient Descent, GD], 以使梯度下降更具一般性.

开始之前, 先放 2 个基本概念, 带着这 2 个认识, 在几乎不具备机器学习知识的前提下, 应该也能很好地读懂本节内容:
机器学习的主要任务之一, 就是通过训练, 习得一组最优的参数. 常以成本函数 [Cost Function] 作为参数估计的函数, 因此, 机器学习的任务就转变为了最小化成本函数.
优化是机器学习算法非常重要的组成部分, 几乎每个机器学习算法都有一个优化算法.
梯度下降算法就是一个被广泛使用的优化算法, 它可以用于寻找最小化成本函数的参数值. 用中学数学的语言来描述梯度下降, 是这样的: 当函数 _ 取得最小值时, 求所对应的自变量 的过程_ 此处, 就是机器要学习的参数, 就是用于参数估计的成本函数, 是关于 的函数. 因此, 基本上具备中学数学知识的, 都能理解梯度下降算法.
梯度下降的基本步骤是:
对成本函数进行微分, 得到其在给定点的梯度. 梯度的正负指示了成本函数值的上升或下降:
选择使成本函数值减小的方向, 即梯度负方向, 乘以以学习率 计算得参数的更新量, 并更新参数:
重复以上步骤, 直到取得最小的成本
以上就是梯度下降算法最基础也是最核心的概念, 很简单吧.
下面讲讲梯度下降算法的几个变种, 包括: 批量梯度下降 [Batch Gradient Descent, BGD], 随机梯度下降 [Stochastic Gradient Descent, SGD], 小批量梯度下降 [Mini-Batch Gradient Descent, MBGD]
算法简介
BGD
BGD 是梯度下降算法最原始的形式, 其特点是每次更新参数 时, 都使用整个训练集的数据.
BGD 的具体实现是这样的:
设假设函数为:
所谓假设函数, 就是用于将输入映射为输出的工具, 其返回值也称为估计值
设成本函数为:
注意, 才是函数自变量, 是模型输入, 是输入对应的真实值
该成本函数中, 真正有效的部分是 , 前面的 是为后续计算方便添加的
对成本函数求导, 需要对每一个参数 分别求偏导, 得到它们各自的梯度:
机器学习模型通常不止一个参数. 成本函数作为参数估计的工具, 要估计每个参数的最优值, 因此需要对每一个参数分别求偏导数
每个参数都按梯度负方向进行更新:
因此, BGD 的伪代码形式可以简单地写成:
repeat {
(for every j = 0, 1, .. n)
}
上式中的求和部分 就体现了每一次迭代, 都以整个训练集为对象进行梯度计算.
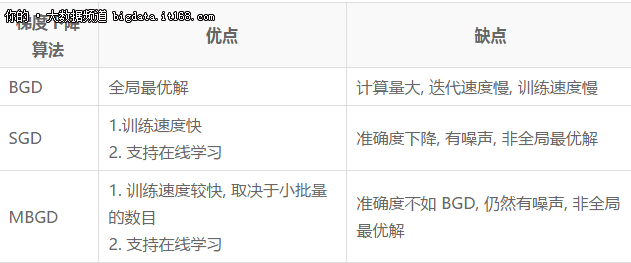
BGD 得到的是全局优秀的解决方案, 因为它总是以整个训练集来计算梯度, 这是 BGD 的优点. 但也因此带来了巨大的计算量, 计算迭代速度很很慢.
SGD
SGD 每次以一个样本, 而不是整个数据集来计算梯度. 因此, SGD 从成本函数开始, 就不必再求和了, 针对单个样例的成本函数可以写成: (此处的 同样是为了后续计算方便设置的)
于是, SGD 的参数更新规则就可以写成:
SGD 的伪代码形式如下:
repeat {
for i = 1, .., m {
(for every j = 0, 1, .. n)
}
}
SGD 的关键点在于以随机顺序选取样本. 因为 SGD 存在局部最优困境, 若每次都以相同的顺序选取样本, 其有很大的可能会在相同的地方陷入局部困境, 或者收敛减缓. 因此, 欲使 SGD 发挥更好的效果, 应充分利用随机化 [Randomise] 带来的优势: 可以在每次迭代之前 (伪代码中最外围循环), 对训练集进行随机排列.
因为每次只取一个样本来进行梯度下降, SGD 的训练速度很快, 但会引入噪声, 使准确度下降. 这意味着并不是每次迭代都向着全局最优而去, 即并不是每次迭代都能使成本函数值降低. 不过换个思路的话, 噪声在一定程度上以使算法避免了局部最优.
SGD 的另一个好处是, 可以使用在线学习 [online learning]. 也就是说, 在模型训练好之后, 只要有新的数据到来, 模型都可以利用新的数据进行再学习, 更新参数,以适应新的变化.
MBGD
MBGD 是为解决 BGD 与 SGD 各自缺点而发明的折中算法, 或者说它利用了 BGD 和 SGD 各自优点. 其基本思想是: 每次更新参数时, 使用 n 个样本, 既不是全部, 也不是 1. (SGD 可以看成是 n=1 的 MBGD 的一个特例)
此处就不再给出 MBGD 的成本函数或其求导公式或参数更新规则公式了, 基本同 BGD, 见上.
MBGD 的伪代码如下:
say b=10, m=1000,
repeat {
for i = 1, 11, 21, .., 991 {
(for every j = 0, 1, .. n)
}
}
总结一下以上3个梯度下降算法的优缺点:
梯度下降算法
Tips
下面将介绍一些梯度下降算法的使用技巧:
挑选合适的学习率 . 最好的选择方法就是监测目标函数值 (本文中就是成本函数值) 随时间的学习曲线.
绘制成本-时间的曲线, 观察成本随迭代的变化情况, 即梯度的变化情况. 若成本没有随着迭代而下降, 说明学习率过大了 (发散了).
学习率通常是一个很小的实值, 比如 0.1, 0.001, 0.0001. 学习率如果过大, 成本函数可能无法收敛, 一直处于发散状态.
学习算法之前, 进行特征缩放能够改善梯度下降. (亲测! 原来使用较大学习率, 成本函数无法收敛; 使用特征缩放之后, 收敛了)
使用 MBGD 时, 在学习过程中, 可以逐渐增大小批量的大小, 更好地综合发挥 BGD 与 SGD 的优势.
进阶
(以下内容有点深奥, 笔者对一些概念也不甚熟悉, 仅仅是做个记录)
我注意到 Keras 实现的 SGD 提供了 3 个关键字参数: decay, momentum, nestrov:
decay–衰减的意思, 表示每一次迭代, 学习率 的衰减量.
momentum–动量的意思, 旨在加速学习, 稍后介绍.
nesterov–算法名, 表示是否使用 Nesterov 动量算法.
使用 BGD 达到极小值时, 整个成本函数的真实梯度会变得很小, 最终减小为 0, 因此 BGD 可以使用固定的学习率; 然而, SGD 中梯度估计引入的噪声源不会在极小点处消失, 因此有必要随着时间的推移逐渐降低学习率, 以保证 SGD 收敛.
实践中, 一般让学习率线性衰减, 直到第 次迭代:
其中, 表示第 k 次迭代, 表示第 次迭代, .
上式中, 需要设置的量包括: 初始学习率 , 最终学习率 以及 终止迭代次数 . 通常取几百的大小, 则设为 的 . 因此, 剩下的主要问题就是选择一个合适的 : 取值太大, 学习曲线会剧烈抖动, 成本会明显增加; 取值太小, 学习过程会变得很缓慢.
上面提到, 在梯度下降中引入动量的概念, 是为了加速学习, 特别是对于处理高曲率 (曲率: 曲线偏离直线的程度), 小但一致的梯度, 或者带噪声的梯度, 有明显的加速效果. 因为动量算法积累了之前梯度指数级衰减的移动平均 (移动平均: 分析时间序列数据的有效工具), 能够继续沿该方向移动, 从而使成本持续减小.
从形式上看, 动量算法引入了 充当速度的角色, 代表参数在参数空间移动的方向和速率. 被设为负梯度的指数衰减平均, 其更新规则如下:
从上式可以得出的一个结论是: 相对于 , 越大, 之前梯度对现在方向的影响就越大.
在引入动量的概念之前, 的更新步长只是梯度范数乘以学习率, 引入动量之后则取决于梯度序列的大小和排列. 当许多连续的梯度指向相同时, 步长最大
Nesterov 动量算法是标准动量算法的变种, 其更新规则如下:
Nesterov 动量算法与标准动量算法的区别在于梯度的计算, 其梯度计算是在施加了当前速度之后, 可以解释为向标准动量方法中添加了一个校正因子.
题外话
研究优化算法的收敛率时, 一般会衡量额外误差: , 即当前成本超出最低可能成本的量. SGD 应用于凸问题 (研究定义于凸集中的凸函数最小化的问题)时, k 步迭代的额外误差量级是 , 在强凸情况下是 . 除非假定额外条件, 否则不能进一步改进.
Cramer-Rao 界限指出, 泛化误差的下降速度不会快于 . Bottou and Bousquet 因此认为机器学习任务, 不值得探寻收敛快于 的优化算法, 因为:
更快的收敛可能对应过拟合
样例代码
以下是 BGD, SGD, MBGD 的 Python 代码实现, 暂时不包括进阶部分提到的高级内容.
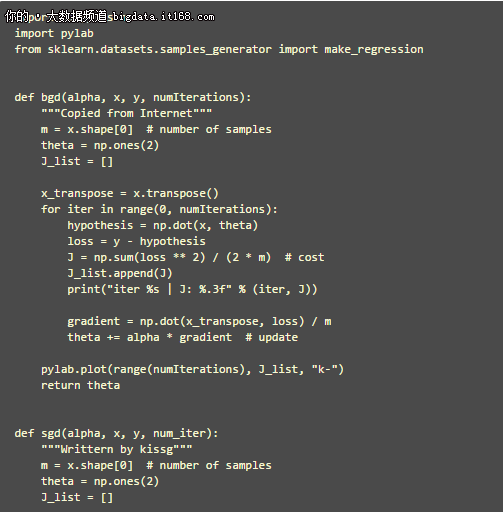
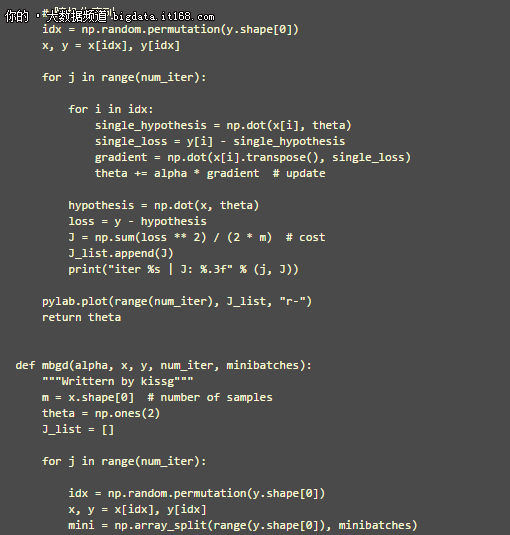
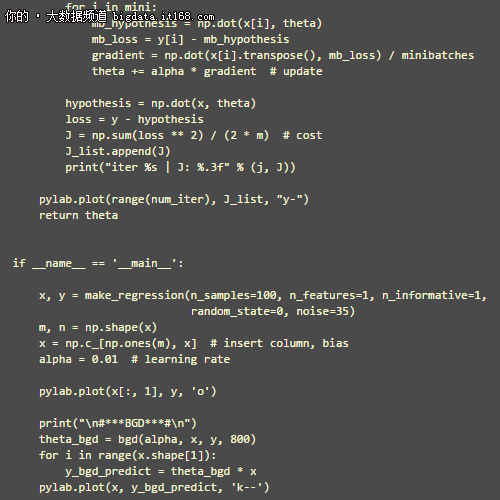
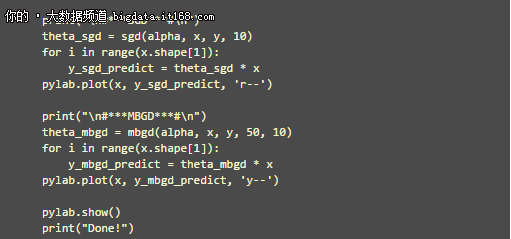
执行以上代码, 得到 3 类梯度下降算法的函数图像如下图所示.
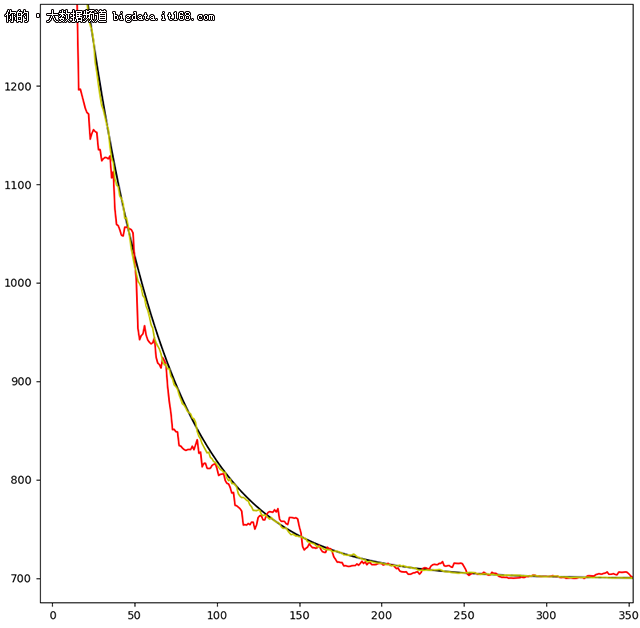
黑色是 BGD 的图像, 是一条光滑的曲线, 因为 BGD 每一次迭代求得的都是全局优秀的解决方案;
红色是 SGD 的图像, 可见抖动很剧烈, 有不少局部优秀的解决方案;
黄色是 MBGD 的图像, 相对 SGD 的成本-时间曲线平滑许多, 但仔细看, 仍然有抖动.

