百分点认知智能实验室:疫情情绪识别大赛的亚军是如何炼成的
编者按:为助力疫情防控和疫情之后的经济社会恢复工作,推动北京市政府数据开放,吸纳大数据产业顶尖社会资源,充分释放专业人才智慧资源,北京市经济和信息化局、中国计算机学会大数据专家委员会联合主办科技战疫·大数据公益挑战赛。
百分点认知智能实验室参加了该挑战赛中的“疫情期间网民情绪识别“比赛,该赛题也是第二十六届全国信息检索学术会议 (The 26th China Conference on Information Retrieval, CCIR 2020)评测大赛赛题。经过长达2个多月的激烈角逐,百分点认知智能实验室从2049支参赛队伍中脱颖而出,取得了A榜第1,B榜第2的成绩,并且通过决赛的答辩,获得了该比赛的亚军。
本文作者:易显维、苏海波
1、背景介绍
2019新型冠状病毒(COVID-19)感染的肺炎疫情发生对人们生活生产的方方面面产生了重要影响,并引发国内舆论的广泛关注,众多网民参与疫情相关话题的讨论。为了帮助政府掌握真实社会舆论情况,科学高效地做好防控宣传和舆情引导工作,主办方组织了“疫情期间网民情绪识别”的评测大赛,吸引了2049支队伍的参加,包括各大知名高校以及大数据和人工智能企业。
具体的赛题任务是给定微博ID和微博内容,设计算法对微博内容进行情绪识别,判断微博内容是积极的、消极的还是中性的,具体可以见下图1。同时本赛题也是第二十六届全国信息检索学术会议 CCIR 2020评测大赛赛题。

图1. 赛题任务介绍
2、方案概述
首先是数据分析,我们发现比赛数据的特点是微博口语化严重、存在表情符、配图随意性强,而且存在分类标准模糊、图片和文本数据混合等众多挑战,具体见下图2。
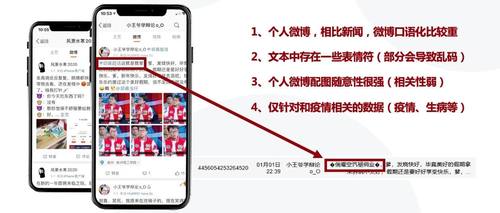
图2. 比赛数据特点(微博)在比赛过程中,我们分析出了此次赛题的三个挑战,首先是文本情绪的分类标准较为模糊,且文本字段中有较多干扰;其次图片特征和时间戳特征需要考虑到模型中去;除此技术方面的挑战之外,此任务为文本分类典型任务,竞争非常激烈。我们的参赛方案中结合当下流行的深度学习和文本处理方法,构建了情绪识别模型,整体技术路线见下图3。
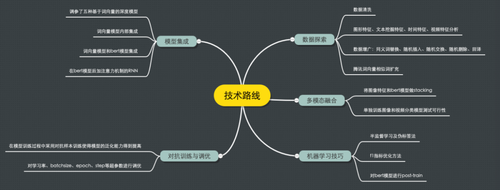
图3. 比赛方案的整体技术路线在接下来的内容中,我们首先介绍了在数据探索和方案策略上的工作,然后介绍本方案的最终算法策略,主要包括:1. 数据探索(包括数据清洗和数据增强);2. 多模态特征融合;3. 机器学习技术(包括半监督学习伪标签法和Post-training方法);4. 对抗训练;5. 模型集成,下面展开详细介绍。
3、数据探索
数据探索主要包括数据清洗和数据增强两部分。
数据清洗首先我们经过统计分析发现诸如“转发微博”、“网页链接”和“展开全文”这些关键字与预测结果没有相关性,实验结果说明,应该直接用空字符串替换,画图分析结果如下图4所示;其次是发现微博内容中有诸如回复**和@**这样的结构,后面的**表示人名,而人名往往很长,这些无意义的字会对语义产生干扰,我们统一将这两个•结构用@这一个字符进行替换;另外,我们还对文字进行了繁简替换处理以及删除重复数据条目处理。
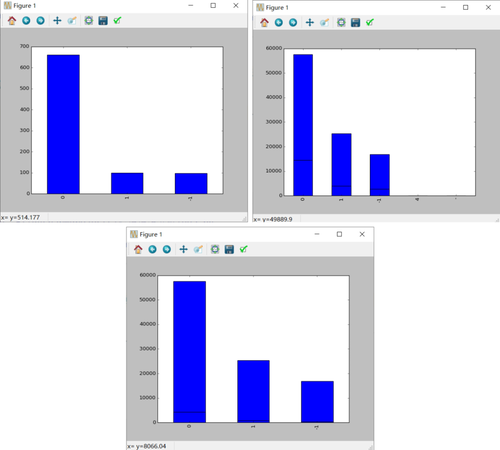
图4. 原标记数据、转发微博和含有网址链接的标签分布
数据增强
数据增强我们尝试了两种方式,第一种是同义词替换、随机插入、随机交换、随机删除结合的方式,代码参考了方法[1];第二种是回译法,即将训练集中的文本数据通过百度翻译API翻译成英文和日文后,再翻译成中文,得到新数据集后对原有训练集做数据扩充。在数据探索的实验中,我们将原训练集划分成了训练集、测试集和验证集,下表是数据增强的实验结果,发现效果并不理想。
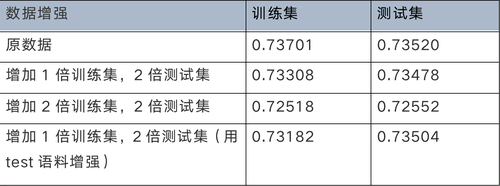
表1 数据增强实验结果
4多模态融合
我们尝试采用DenseNet121在ImageNet数据集上的预训练权值作为图像特征提取器,BERT-Base模型输出结果做stacking之后发现并无提升。另外,我们采用DenseNet121在本数据的图片数据集上进行分类训练,分类效果对比随机得分有较大提升,但是将结果集查看分布得知,该网络结构并不能从图片中有效提取本赛题的特征,预测结果分布如下图5,可知预测都为0值,说明图片特征在本赛题中无明显效果。

图5 图片分类器的预测结果
我们对多模态融合为什么效果不好进行了具体的分析,详细的原因见下图6。

图6 多模态融合效果不好的原因分析
5、机器学习技术
半监督学习伪标签法
由于本题中提供了90w未标记数据,为了充分利用数据,我们利用伪标签法,使用已训练的模型对90w数据进行一次性预测,生成标记结果,然后从90w数据集中选取置信度较高的混入到标记数据中进行训练。同时我们还多次调整了混合比例,但发现该方法提升不明显,分析原因如下图7所示:图中为预测第三列(-1,0,1)数据分布,可见0(中性)的分布和1、-1两类相比有很大不同,说明要判断为1和-1的数据置信度较低,当该数据混入原标记数据中训练的时候会将误差放大。
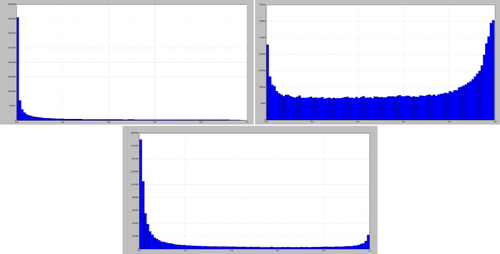
图7. 预测第三列(-1,0,1)数据分布Post-training方法接下来,重点介绍一下我们在本次比赛当中使用的Post-training方法,该方法来自论文[4],它的主要思想是结合领域数据,对BERT-Base模型进行微调,学习该领域知识,改进BERT-Base模型与特定领域的匹配程度,因为BERT-Base模型是通过维基百科语料训练的,所以它缺乏特定领域的知识,例如本次比赛中的微博数据知识。经过实验,Post-training是比较有效果的,相比BERT-Base模型,大约有0.8个百分点的F1值提升。
6对抗训练
为了提升模型的预测稳定性,我们还采用了对抗训练的技术。它的主要思想是提升模型在小扰动下的稳定性,比如下图6中的每一个点代表一个数据样本,它通过对抗训练之后,可以明显看到每一个数据点都落在一个小的坑里面,这样它的模型泛化能力就被增强了。
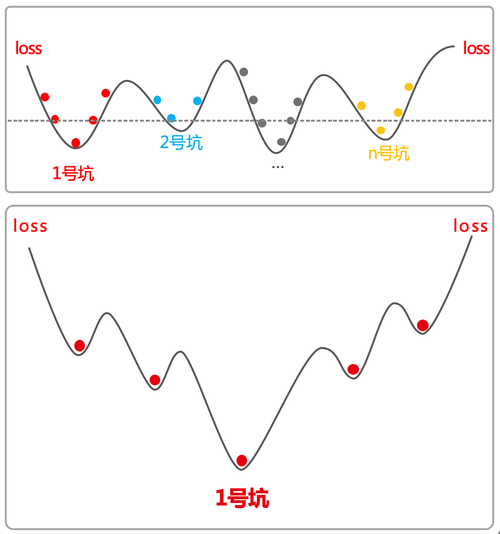
图8. 对抗训练的示意图
近年来,随着深度学习的日益发展和落地,对抗样本也得到了越来越多的关注。NLP中的对抗训练是作为一种正则化手段来提高模型的泛化能力。对抗样本首先出现在论文[3]之中。简单来说,它是指对于人类来说“看起来”几乎一样、但对于模型来说预测结果却完全不一样的样本。
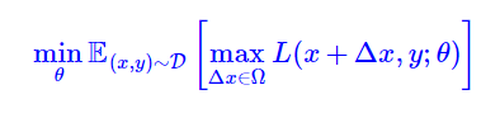
其中D代表训练集,x代表输入,y代表标签,θ是模型参数,L(x,y;θ)是单个样本的loss,Δx是对抗扰动,Ω是扰动空间。这个统一的格式首先由论文[3]提出。实验结果显示:在Embedding层做对抗扰动,在很多任务中,能有效提高模型的性能。进行对抗学习的时候,我们需要将dropout设置成0,即固定网络结构,使得对抗学习在固定的网络结构中进行。通过我们的实验,在比赛中的效果大约能够提升0.5个百分点。
7、模型集成
多折模型集成
我们采用了F1值适应优化以及多折模型融合的技术,这两个技术都有明显的效果提升。F1值适应技术的主要思想是准确度最高的模型,它的F1值并非最大,所以我们在输出结果的时候,前面乘一个权重,然后通过非线性优化的方法使得F1值最大。在模型融合方面,经过实验,5到7折能够取得最好的效果。
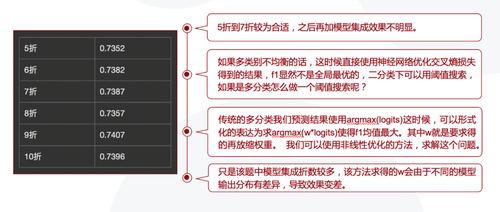
图9. 多折模型集成的效果
词向量模型
将标记数据、未标记数据和测试集合中的文本数据合并后作为词向量的训练语料,得到词向量文件。经过观察,该词向量质量较好,例如查看“发烧”的近义词,系统输出如下:[('低烧', 0.705), ('流鼻涕', 0.651), ('高烧', 0.635), ('鼻塞', 0.630), ('发高烧', 0.627), ('喉咙痛', 0.609), ('拉肚子', 0.599), ('嗓子疼', 0.575), ('感冒', 0.574), ('发热', 0.570)]。
本方案中尝试了五种基于词向量的深度学习模型:1. 一维卷积模型;2. 多个不同的卷积核的模型;3. RNN模型,4. 双向GRU模型;5. 有注意力机制的RNN模型,经过测试,发现得分均没有能超过BERT-Base模型。之后还尝试与BERT-Base模型做stacking集成,得分相比BERT-Base也有下降。
8、整体方案
通过各种技术的尝试和实验,我们最终的算法方案是Post-Training、对抗训练、F1适应优化和模型集成等多种技术的融合,取得了A榜第一、B榜第二的良好成绩,整体方案的流程图如下图10所示,该方案在执行效率方面,算法离线模型训练只需要40分钟,实时预测速度为0.1秒,执行效率高,实用性强。
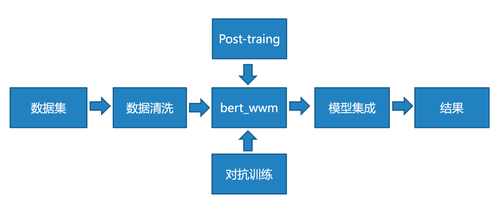
图10. 方案整体流程图
内容小结
最后,我们总结一下本算法方案的应用有效性、价值潜力和创新性。在应用效果方面,该算法的F1值在A榜第一,B榜第二,均排名前列,有很好的应用效果;在价值潜力方面,该算法的应用效果好、执行效率高、扩展性好,因此非常容易落地,有良好应用前景;在技术新颖性方面,本方案采用了对抗攻击提升模型稳定性,采用Post-Training技术提升预训练模型和特定领域匹配度,达到良好的效果。

