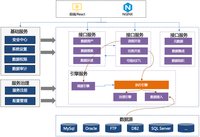
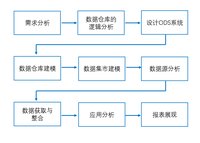
- 以大数据操作系统为例 解读ToB产品架构设计的挑战及应对方案
随着企业及政府数字化转型升级,越来越多的科技公司开始进入ToB行业。ToB产品因为其独特的性质,与传统ToC互联网应用架构的设计有着很多不同。
覃里 · 2022-09-05 10:06  数据湖方案五花八门,实际落地如何选型和构建?
数据湖方案五花八门,实际落地如何选型和构建?最初企业存储数据都在数仓中存储,但是随着数据量的增大,传统数据的方案在时效性上和数据维护上变得越来越困难。实时数仓架构应运而生。但具体方案落地上它有很多方案可选,那么面对不同的业务和应用场景我们到底应该选择哪种技术方案呢?这是困扰好多大数据架构师的问题。今天就此来跟大家探讨一下。
韩楠 · 2022-04-19 18:04- “中国数谷”日新月异,贵阳“智”绘数字蓝图
千载夜郎,悠悠黔城,在数字经济时代焕发出新的光彩。正是基于把大数据先发优势转化为未来的发展胜势的全面布局,贵阳持续用好“中国数谷”这张名片,源源不断地在大数据引领创新驱动发展上实现新作为、取得新进展,带来了实实在在的发展实绩和民生实惠。
卢敏 · 2021-05-24 10:30 - 百分点大数据技术团队:数据治理“PAI”实施方法论
数据作为第五大生产要素,已逐渐成为政府和企业决策的重要手段与依据。面对数据多样化、数据需求个性化、数据应用智能化的需求,以及在2B和2G行业中数据质量参差不齐、数据应用难以发挥价值、数据资产难以沉淀等问题,如何做好数据治理工作、提升数据治理能力成为了政府和企业数字化转型的重中之重。百分点大数据技术团队基于多年的数据治理项目经验,总结了一套做好数据治理工作及提升数据治理能力的实施方法论。
任朝阳 · 2021-03-30 13:06 - HDFS分布式存储中NameNode 和DataNode 有什么区别?
目前市场中,HDFS分布式存储系统是很热门的讨论话题,各种企业也倾向于搭建分布式存储系统。
任朝阳 · 2020-09-16 10:25 - 如何做好一个BI项目的规划和需求定义?
正所谓磨刀不误砍柴工,一个项目的启动,先得从金字塔顶端做好规划,摸清楚需求、背景、客观条件、可投入资源等。本文,BI项目详解的第一篇,先来谈谈BI项目的规划和需求定义。
任朝阳 · 2020-09-08 09:39 - 哇,ElasticSearch多字段权重排序居然可以这么玩
读者提问:ES 的权重排序有没有示列,参考参考?刚好之前也稍微接触过,于是写了这篇文章,可以简单参考下。
任朝阳 · 2020-08-27 18:19 - 百分点大数据技术团队:乘风破浪 海外数据中台项目实践
响应“一带一路”倡议,百分点自2016年开始开拓海外业务,三年时间,百分点海外团队在非洲某国实施大数据项目并取得阶段性验收。
任朝阳 · 2020-08-18 17:22 - 百分点认知智能实验室:疫情情绪识别大赛的亚军是如何炼成的
为助力疫情防控和疫情之后的经济社会恢复工作,推动北京市政府数据开放,吸纳大数据产业顶尖社会资源,充分释放专业人才智慧资源,北京市经济和信息化局、中国计算机学会大数据专家委员会联合主办科技战疫·大数据公益挑战赛。
任朝阳 · 2020-07-31 16:08 - 记一次上千节点Hadoop集群升级过程
Hadoop Router针对NameNode的failover没有进行重试处理,在主备切换期间,服务报错,整体不可用。Hadoop addBlock 在3.2.1版本的设计思路上会因为机架策略的问题,进行循环处理,导致CPU占用很高,加锁频率很高。
任朝阳 · 2020-07-24 21:54 - 新基建时代下的大数据中心变革:创新和开放是发展方向
当前,云数据库厂商正在借助“新基建”的东风乘势而上,以抓住新时代下的发展机遇。成思敏表示,希望在行业各领域的共同努力下,云数据中心能够成本更低、性能更无界、更安全、更智能。
卢敏 · 2020-06-11 17:45 - 从初创到顶级技术公司,都在用哪些数据科学技术栈?
如果你正在组建一个新的团队、组织或公司的时候,一开始你可能需要效仿某个现成的技术栈,再依据需求来构建自己的技术栈,还需要对一些过时的技术进行升级。
任朝阳 · 2020-05-13 09:38 - 一份关于机器学习“模型再训练”的终极指南
机器学习模型的训练,通常是通过学习某一组输入特征与输出目标之间的映射来进行的。一般来说,对于映射的学习是通过优化某些成本函数,来使预测的误差最小化。在训练出最佳模型之后,将其正式发布上线,再根据未来生成的数据生成准确的预测。这些新数据示例可能是用户交互、应用处理或其他软件系统的请求生成的——这取决于模型需要解决的问题。在理想情况下,我们会希望自己的模型在生产环境中进行预测时,能够像使用训练过程中使用的数据一样,准确地预测未来情况。
谢涛 · 2019-12-31 17:52 - 合理建立Hadoop数据湖的7个步骤
数据湖的概念起源于大数据的出现——且数据已成为企业的核心资产,Hadoop则是作为存储和管理数据的平台而出现。但是,盲目地投入Hadoop数据湖建设并不一定会使您的企业进入大数据时代——至少不是以一种成功的方式。
谢涛 · 2019-11-18 17:23