- 阿里巴巴资深大数据工程师:大数据处理实践
不同于以往的授课式课堂风格,这次斯坦福大学的教授Hadley Wickham开设了一门论文讨论课。课程名为:Readings in Applied Data Science。要求学生每周阅读3~4篇论文,并给出反馈。
赵钰莹 · 2018-06-10 19:33 - Python数据预处理:Dask和Numba并行化加速!
如果你善于使用Pandas变换数据、创建特征以及清洗数据等,那么你就能够轻松地使用Dask和Numba并行加速你的工作。单纯从速度上比较,Dask完胜Python,而Numba打败Dask,那么Numba+Dask基本上算是无敌的存在。
赵钰莹 · 2018-06-07 05:00 - 大数据存储平台之异构存储实践深度解读
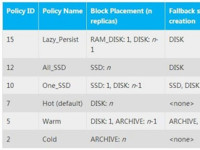
经常做数据处理的伙伴们肯定会有这样一种体会:最近一周内的数据会被经常使用到,而比如最近几周的数据使用率会有下降,每周仅仅被访问几次;在比如3月以前的数据使用率会大幅下滑,存储的数据可能一个月才被访问几次。
赵钰莹 · 2018-06-07 05:00 - 刘博宇:Druid在滴滴应用实践及平台化建设
Druid是一款支持数据实时写入、低延时、高性能的OLAP引擎,具有优秀的数据聚合能力与实时查询能力。在大数据分析、实时计算、监控等领域都有特定的应用场景,是大数据基础架构建设中重要的一环。Druid在滴滴承接了包括实时报表、监控、数据分析、大盘展示等应用场景的大量业务,作为大数据基础设施服务于公司多条业务线。本次演讲我们将介绍Druid的核心特性与原
赵钰莹 · 2018-06-06 10:09 - Sqoop数据导入到HBase遇上的问题及解决方法
运行bin/sqoop import --connect jdbc:mysql://ip:port/database --username *** --password ****--hbase-bulkload --hbase-create-table --column-family info --hbase-row-key username --hbase-table detects --table detects将Mysql中detects表导入到Hbase中的detects表,提示找不到users Class错误
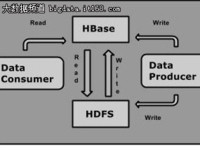
赵钰莹 · 2018-05-31 17:55 - 如何避免HBase写入过快引起的各种问题
直接限制队列堆积的大小。当堆积到一定程度后,事实上后面的请求等不到server端处理完,可能客户端先超时了。并且一直堆积下去会导致OOM,1G的默认配置需要相对大内存的型号。当达到queue上限,客户端会收到CallQueueTooBigException 然后自动重试。通过这个可以防止写入过快时候把server端写爆,有一定反压作用。线上使用这个在一些小型号稳定性控制上效果不错。
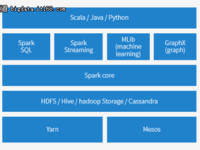
赵钰莹 · 2018-05-31 17:55 - Spark及Spark Streaming核心原理及实践
Spark 已经成为广告、报表以及推荐系统等大数据计算场景中首选系统,因效率高,易用以及通用性越来越得到大家的青睐,我自己最近半年在接触spark以及spark streaming之后,对spark技术的使用有一些自己的经验积累以及心得体会,在此分享给大家。本文依次从spark生态,原理,基本概念,spark streaming原理及实践,还有spark调优以及环境搭建等方面进行介绍,希望对大家有所帮助。
赵钰莹 · 2018-05-31 17:54 - 如何在万亿级别规模的数据量上使用Spark?
Spark作为大数据计算引擎,凭借其快速、稳定、简易等特点,快速的占领了大数据计算的领域。本文主要为作者在搭建使用计算平台的过程中,对于Spark的理解,希望能给读者一些学习的思路。文章内容为介绍Spark在DataMagic平台扮演的角色、如何快速掌握Spark以及DataMagic平台是如何使用好Spark的。
赵钰莹 · 2018-05-30 17:56 - 技术解析:HDFS应用场景、原理和基本架构
HDFS是什么? 易于扩展的分布式文件系统,运行在大量普通廉价机器上,提供容错机制为大量用户提供性能不错的文件存取服务。HDFS是什么? 易于扩展的分布式文件系统,运行在大量普通廉价机器上,提供容错机制为大量用户提供性能不错的文件存取服务。源自于Google的GFS论文发表于2003年10月HDFS是GFS克隆版Hadoop Distributed File System易于扩展的分布式文件系统运行在大量普通廉价机器上
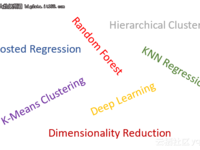
赵钰莹 · 2018-05-25 14:29 - 对数据科学家来说最重要的算法和统计模型
作为一个在这个行业已经好几年的数据科学家,在LinkedIn和QuoLa上,我经常接触一些学生或者想转行的人,帮助他们进行机器学习的职业建议或指导方面相关的课程选择。一些问题围绕教育途径和程序的选择,但许多问题的焦点是今天在数据科学领域什么样的算法或模型是常见的。
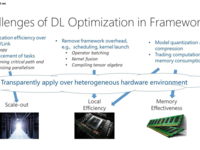
田晓旭 · 2018-05-24 20:23 - 深度:如何从系统层面优化深度学习计算?
在图像、语音识别、自然语言处理、强化学习等许多技术领域中,深度学习已经被证明是非常有效的,并且在某些问题上已经达到甚至超越了人类的水平。然而,深度学习对于计算能力有着很大的依赖,除了改变模型和算法,是否可以从系统的层面来优化深度学习计算,进而改善计算资源的使用效率?本文中,来自微软亚洲研究院异构计算组资深研究员伍鸣与大家分享他对深度学习计算优化的一些看法。
赵钰莹 · 2018-05-24 16:11 - Accordion :一种HBase内存压缩算法介绍
现如今,人们对基于HBase的产品的读写速度要求越来越高。在理想情况下,人们希望HBase 可以在保证其可靠的持久存储的前提下能并拥有内存数据读写的速度。为此,在HBase2.0中引入Accordion算法。
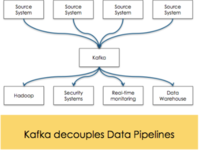
赵钰莹 · 2018-05-22 15:33 - 从程序安装到设置,Kafka的配置属性解析!
Kafka是由Scala和Java编写的最流行的发布者 - 订阅者模型之一。它最初由LinkedIn开发,后来经过开源。Kafka是一种高吞吐量的分布式发布订阅消息系统,因可以处理重负载量的信息而著名。这里从安装到设置为您详解Kafka的各种属性。
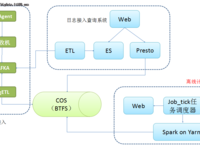
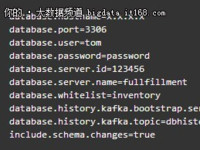
赵钰莹 · 2018-05-22 09:30 - Kafka Connect如何实现同步RDS binlog数据?
本文介绍如何在E-MapReduce上使用Kafka Connect实现同步RDS binlog数据。在我们的业务开发中,往往会碰到下面这个场景:业务更新数据写到数据库中,业务更新数据需要实时传递给下游依赖处理,所以传统的处理架构可能会这样:
赵钰莹 · 2018-05-14 08:57 - 基于Alluxio的HDFS多集群统一入口的实现
随着苏宁大数据平台的规模越来越大,HDFS集群Namenode逐渐出现性能瓶颈,特别是在凌晨任务的高并发期,Namenode的RPC响应延迟较高,单次写RPC请求甚至超过1s,严重影响了集群的计算性能。因此解决HDFS的扩展性问题,势在必行。
赵钰莹 · 2018-05-09 10:27 - Tensorflow快餐教程(8) - 深度学习简史
如果要给机器学习划分流派的话,初步划分可以分为『归纳学习』和『统计学习』两大类。所谓『归纳学习』,就跟我们平时学习所用的归纳法差不多,也叫『从样例中学习』。归纳学习又分为两大类,一类是像我们归纳知识点一样,把知识分解成一个一个的点,然后进行学习。因为最终都要表示成符号,所以也叫做『符号主义学习』;另一类则另辟蹊径,不关心知识是啥,而是模拟人脑学习的过程,人脑咋学咱们就照着学。
赵钰莹 · 2018-05-07 09:08 - 专访陶天林:解读达梦大数据平台的特色
大数据产业在我国已经有了数年的发展,但从整体来看,我国信息化程度还不是特别完善。因此,目前还处于探索的阶段,想要进一步发展还是需要经历一段时间。近几年大数据产业也有很多崛起的大数据公司,各种类型的大数据公司比比皆是,不管什么类型的产品,都号称采用了大数据技术。那么什么是一款好的大数据产品呢? 企业的大数据选型最应该看重哪些因素?我们选那种类型的大数据平台?达梦大数据平台的优势又在哪里?
田晓旭 · 2018-04-23 13:20 - 大数据创新应用:高速公路的数据存储及处理
通过分析信息化建设脉络中高速公路数据的海量产生,结构复杂的海量数据存储及处理,阐述大数据平台在智慧高速建设中的作用,总结大数据在智慧高速中的客户服务、运营优化、稽查分析、应急资源调度、预测预警等方面的具体应用,对交通指挥中心工作提供支持。
覃里 · 2018-04-10 11:23 - 中国邮政大数据平台建设之总体架构与实现
通过对数据处理阶段性发展的解析,分析大数据、人工智能技术的发展趋势。结合实际生产需求,验证了基于容器云架构的新一代大数据与人工智能平台在数据分析、处理、挖掘等方面的强大优势。
覃里 · 2018-04-10 10:27 - 2018年一定要收藏的20款免费预测分析软件!
本文推荐一些免费的预测分析软件,它们主要用于分析统计使用,机器学习和数据挖掘来寻找关于客户行为,市场趋势和原始数据集中其他领域的线索的相关性和模式。其中一些预测建模解决方案可通过许可,免费获得开源或社区版本;其中一些预测分析软件是商业版本的免费版或社区版,但提供的功能较少。
陈毅东 · 2018-02-14 09:00