最新文章
5月27日,深圳市杉岩数据技术有限公司(简称“杉岩数据”)宣布完成亿元级D轮融资。

IDC《Global DataSphere Forecast》报告预计,到2028年,全球数据量将增长至393.9 ZB。其中,中国市场数据量到2029年将增长至136.12 ZB。这一增长趋势给业务连续性、数据保护与治理以及维护成本带来了更大压力,也使得“

合成数据并不能完全取代真实数据,也无法消除对治理的需求。在实践中,让合成数据既实用又安全,本身就是一项运营挑战。内部团队需要一个能够大规模生成合成数据集的环境,将其与微调或评估等特定的AI 任务关联,并实施治理控制,确保输出结果能在企业中被可靠地使用。总体而言

尽管人们正愈发频繁地将信任寄托于各类社会代理媒介,但个体依然拥有塑造自身信息环境的主动权。正如Lu所言,我们如今正处于一个“前所未有的有利位置” —— 能够推动这些系统为人类服务,借助人工智能去探索世界的复杂性,而非满足于非黑即白的简单叙事。

在 2026 年,AI 将真正区分“建设者”与“信奉者”。最终的领先者,将是那些能够把 AI 无缝融入自身数据架构,并以稳固的数据底座、标准化指标体系和可持续治理为基础推动创新的企业。相反,未能打好数据基础的组织,将持续被困在永无止境的试点循环中。

人工智能(AI),尤其是生成式 AI(GenAI),正在改变各类行业的“游戏规则”。麦肯锡研究显示,生成式AI有望为全球贡献约7万亿美元的经济价值,并将AI的整体影响提高近50%。其中,中国将有望贡献约2万亿美元,近全球总量的1/3。AI 的应用速度也仍在加快

现代零售业的运作依赖于数据——从库存管理到欺诈检测,每一次客户互动都会产生信息,这些信息既可以提升业绩,也可能带来风险。在购物高峰期,数据量成倍增长,风险也随之增加。那些将数据的可见性与可控性置于核心的零售商,才能在扩展业务规模、强化安全防护的同时,持续提供消

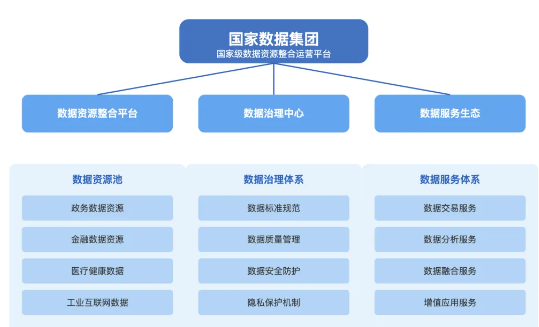
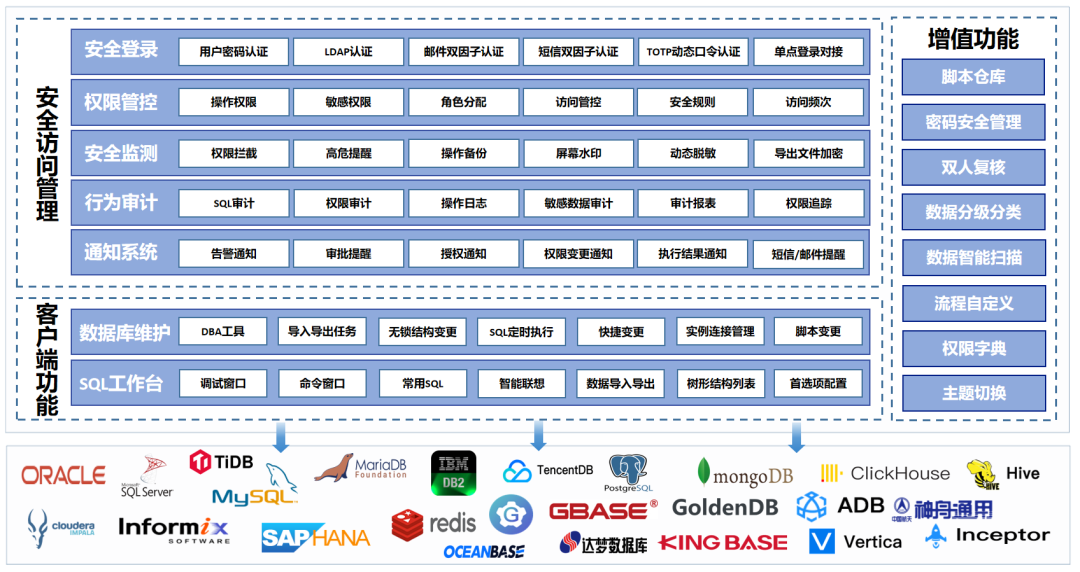
证券行业是高数据价值密度行业。随着数据量的增长,证券公司大数据管理部门面临越来越大的数据安全风险。上海某头部券商数据管理部门以数据访问为抓手,通过建设数据安全访问管理系统,一体化实现了对数据的访问控制、权限管控、动态脱敏和操作审计,大幅提升了大数据平台的安

为推动技术进步,实现数据增长,2024技术卓越奖评选正式公布结果,经过层层严谨筛选,大数据领域的佼佼者——杰出企业、创新解决方案、前沿技术及明星产品全面揭晓。

亲爱的读者,欢迎踏上这段数据觉醒之旅。我是神秘泣男子,一名在数据领域摸爬滚打了十几年的"数据炼金术士"。今天,我想与你分享我的数据中台觉醒之旅,以及我如何将沉睡的数据唤醒,让它们成为推动业务的强大引擎。
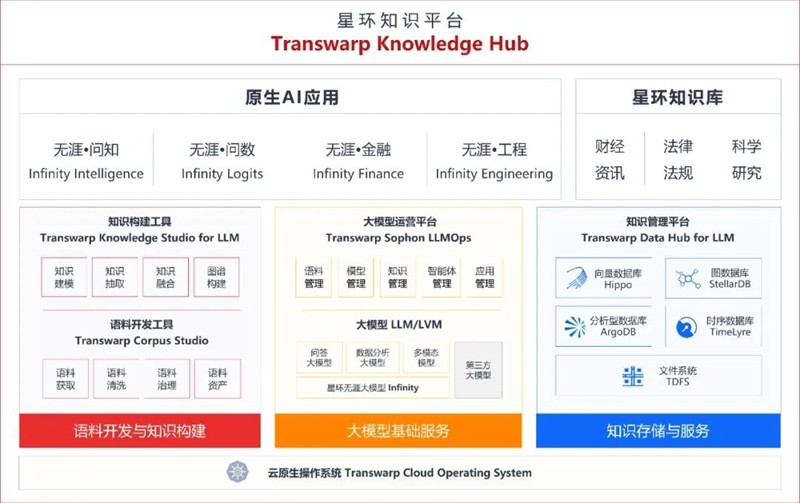
近日,全球领先的 IT 市场研究和咨询公司 IDC 发布《中国大数据平台市场份额,2023:数智融合时代的真正到来》(Doc# CHC51598124,2024年8月)报告,星环科技大数据平台私有化部署市场份额增速第一,并连续4年保持专业厂商市场份额第一。
8月2日,优刻得与上海蔚星数据科技有限公司(下称:蔚星科技)达成战略合作,双方将共同探索云计算与商业航天领域的创新合作,致力于将优刻得智能算力与蔚星科技特有行业数据进行深度融合,构建数据中心、云计算、大数据一体化的新型算力网络体系,共同积极推进算法云平台建设

BI作为IT界“颜值担当”,那可是一直是一项叱咤风云的数据应用技术。曾几何时,为了一张报表、一个大屏,有多少企业都愿意为其“豪掷千金”!为什么现在很多企业又都对其失去了兴趣了呢?

在数字化转型的大潮中,企业对于数据的实时性需求日益增长。尽管传统的离线数据仓库在数据存储和管理方面已经建立了成熟的架构体系,

随着数字经济的蓬勃发展,大数据技术的应用与发展已成为推动企业创新、提升竞争力的关键力量。大数据平台作为数据收集、存储、处理和分析的核心基础设施,
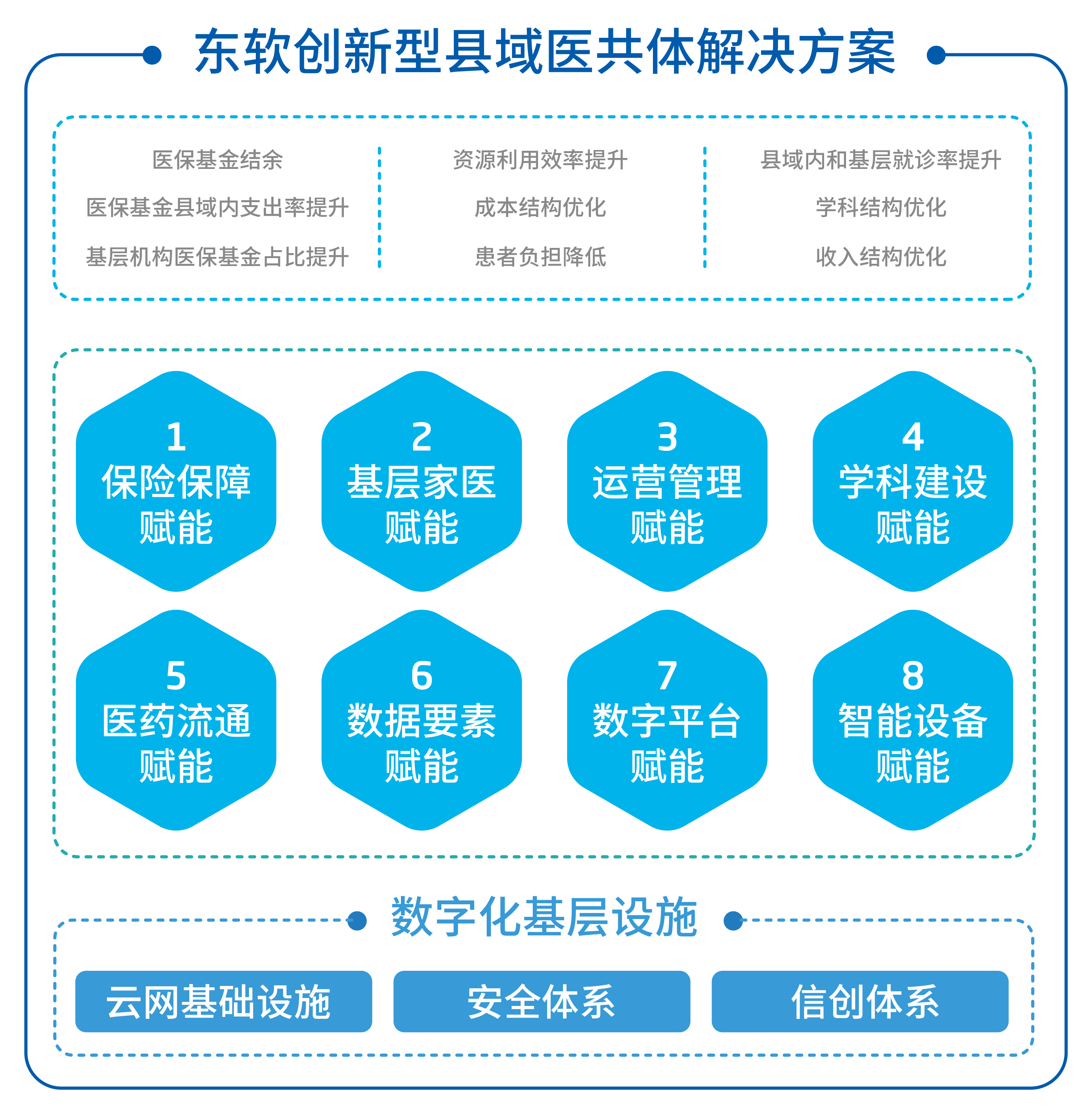
4月24日,东软正式发布“创新型县域医共体解决方案”,并在人民网舆情数据中心/人民在线举办的县域数字医共体建设研讨会上,分享了有关经验和做法。
大数据电子信息产业涵盖以大数据为引领的电子信息制造业、软件和信息技术服务业、通信业,是国民经济的战略性、基础性、先导性产业,是数字经济的核心产业。

