- 主流可选的开源ETL工具清单及优劣说明!
开源ETL工具俨然成为商用解决方案的低成本替代品。就像商业解决方案一样,它们也有其优点和缺点。如果没有时间或资源自定义ETL解决方案或者不能接受商用方案的购买成本,开源解决方案将是一个实用选择。
赵钰莹 · 2018-06-19 08:43 - Hadoop、PostgreSQL与Storm多维度对比!
在“Hadoop是否已失宠?”的选题调研中,笔者调查了银行、Hadoop发行商、Hadoop企业用户以及部分工程师的意见,所处环境、业务需求以及看问题角度的不同让这些组织或个人有着不同的意见。如果你的数据量和增长速度还未达到使用Hadoop的级别,你一定会认为Hadoop是十分不明智的选择;相反,当你已经从Hadoop生态受益良久时,你一定会认为这是大数据时代最佳解决方案之一,比如那些从PostgreSQL迁移至Hadoop的企业。
赵钰莹 · 2018-06-19 08:39 - 机器学习之 Anomaly Detection 异常检验
现实生活中异常检测的应用非常广泛,作为机器学习算法的一种常见应用,从银行安全到自然科学,从药学到营销,从金融工程到计量经济学,都能看到它的踪影,在今天数据领域爆炸式发展的时刻,异常检测更是人工智能一种形式的体现。
赵钰莹 · 2018-06-15 17:39 - 科普文:银行业9大数据科学应用案例解析!
在银行业中使用数据科学不仅仅是一种趋势,它已成为保持竞争的必要条件。 银行必须认识到,大数据技术可以帮助他们有效地集中资源,做出更明智的决策并提高绩效。以下我们罗列银行业使用的数据科学用例清单,让您了解如何处理大量数据以及如何有效使用数据。
赵钰莹 · 2018-06-14 16:47 - 苏宁易购:Hadoop失宠前提是出现更强替代品
在笔者持续调研国内Hadoop生态系统生存现状的同时,KDnuggets发布的2018年数据科学和机器学习工具调查报告再次将“Hadoop失宠”言论复活。报告一出,“Hadoop被抛弃”几个字瞬时成为各大标题党的最爱,充斥在不同的新闻平台。这些报告和数据是否足以动摇Hadoop在国内大数据领域的事实标准地位?本身并不擅长处理OLAP计算和ms级延迟要求的流计算,这是否会成为企业弃用Hadoop的重要原因?
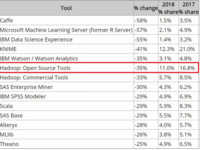
赵钰莹 · 2018-06-13 18:11 - 2018数据科学和机器学习调查:Hadoop被抛弃!
近日,著名数据科学网站 KDnuggets 发布了 2018 年数据科学和机器学习工具调查结果。超过 2000 人对自己「过去 12 个月内在项目开发中使用过的数据挖掘/机器学习工具和编程语言」进行了投票。该统计还对过去三年来的排名进行了对比分析。
赵钰莹 · 2018-06-11 18:04 - 机器学习时代哈希算法如何高效索引数据?
哈希算法一直是索引中最为经典的方法,它们能高效地储存与检索数据。但在去年 12 月,Jeff Dean 与 MIT 等研究者将索引视为模型,探索了深度学习模型学习的索引优于传统索引结构的条件。本文首先将介绍什么是索引以及哈希算法,并描述在机器学习与深度学习时代中,如何将索引视为模型学习比哈希算法更高效的表征。
赵钰莹 · 2018-06-10 19:28 - 学完68个Python函数,为啥还做不好数据分析?
数据分析老鸟都知道,相比于自己作出好的数据分析报告,“教别人如何入门数据分析”这事情简单多了。什么for循环,def函数,print输出,自变量a赋值,字符串和数字转换,相关分析,回归分析,方差分析,聚类分析,判别分析,决策树分析等。函数太多,方法太多,套路太多,技巧太多……可现实是,大多数人听了无数道理依旧庸碌一生,学完68个Python常见函数却依旧做不好数据分析。
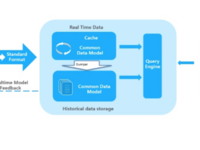
赵钰莹 · 2018-06-08 08:58 - 实践:大数据平台1.0总结和2.0演化路线
从3月份到现在2个月过去了,整个数据平台从0到1,算是有了一个基本的样子,跌跌撞撞的勉强支撑起运营的一些基本业务,当然这仅仅是开始,下一步还要从零打造自己的UBS系统,想想都兴奋呢!接下来总结下自己这段时间的得失,以及下一阶段的演化目标。
赵钰莹 · 2018-06-06 10:00 - Hadoop大数据面试题全版本,必看跳槽指南!
以下资料来源于互联网,很多都是面试者们去面试的时候遇到的问题,我对其中有的问题做了稍许修改了并回答了部分空白问题,有些考题出的的确不是很好,但也不乏有很好的题目,这些都是基于真实面试而来,希望对即将面试或想继续学习hadoop,大数据等方向的朋友有所帮助!
赵钰莹 · 2018-06-06 09:52 - 零售业强竞争,大数据如何帮助弱者角逐
大数据时代,数据分析已经渗透到各行各业,这里也包括零售行业。目前,各大中小型零售商都在努力为客户提供更好的购物体验,用有限的预算为顾客提供满意的服务。零售商业内存在很强的竞争压力,不断的技术创新使得行业景观变化迅速。
赵钰莹 · 2018-06-05 10:01 - 深度:Hadoop对Spark五大维度正面比拼报告!
每年,市场上都会出现种种不同的数据管理规模、类型与速度表现的分布式系统。在这些系统中,Spark和hadoop是获得最大关注的两个。然而该怎么判断哪一款适合你?如果想批处理流量数据,并将其导入HDFS或使用Spark Streaming是否合理?如果想要进行机器学习和预测建模,Mahout或MLLib会更好地满足您的需求吗?
赵钰莹 · 2018-06-01 17:12 - 阿里云封神:Gartner看衰的并不是Hadoop生态
在过去几个月的走访调研中,针对Gartner《2017年数据管理技术成熟度曲线》做出的Hadoop“即将在到达生产成熟期之前衰落”的结论,笔者询问了数十位大数据领域技术专家的观点,Hadoop在国内大数据市场的地位正如笔者所预料的一样稳固。既然如此,那么是Gartner的结论有误吗?我们应该如何正确解读这份报告?抛开报告,Hadoop生态各组件到底表现如何呢?
赵钰莹 · 2018-06-01 16:16 - 麦肯锡:人工智能应用是由少数派推动的
“人工智能的实际采用是由少数派来推动的。”很多人可能不相信这句话,但是根据麦肯锡2017年6月公布的报告,AI投资现在是类似谷歌和百度这样的巨头公司的天下。另外,虽然人工智能很火,但是绝大多数的公司现在还没采取任何实际步骤。根据Gartner的2018年CIO议程调查,全球仅有4%%的CIO实施了AI,而46%%的人已经制定了AI计划。
田晓旭 · 2018-05-30 17:32 - 三大知名银行探讨:AI是伪需求还是真需要?
银行拥有海量数据,多维度的应用系统,这使得其在人工智能技术上有很大发展空间。加拿大皇家银行数据及分析技术高级副总裁Neil Bartlett表示,我们现在看到的不仅是一项技术、一个系统,对银行来讲,我们需要看整个创新风貌,判断如何使用各种创新和技术推动银行业绩的改造。
赵钰莹 · 2018-05-29 14:24 - 国外银行Hadoop态度调查,Gartner所言非虚!
经历了近三个月对国内厂商及企业用户的走访调研,笔者发现国内大部分厂商及企业对Hadoop,尤其是其核心组件的未来十分看好,并且Hadoop已经成为国内大多数互联网公司和大数据厂商基础架构中很重要的一部分,似乎并未把Gartner的“Hadoop在到达生产成熟期之前即会被淘汰”的结论放在心上。然而,在近期对国外大数据厂商Teradata及其两大银行客户——富国银行和加拿大皇家银行的采访中,笔者收到了与国内用户截然不同的反馈。
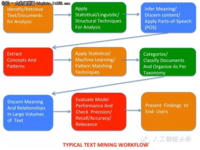
赵钰莹 · 2018-05-28 17:26 - 借助亚马逊S3和RapidMiner应用到文本挖掘
本挖掘典型地运用了机器学习技术,例如聚类,分类,关联规则,和预测建模。这些技术揭示潜在内容中的意义和关系。文本发掘应用于诸如竞争情报,生命科学,客户呼声,媒体和出版,法律和税收,法律实施,情感分析和趋势识别。
田晓旭 · 2018-05-28 14:55 - 基础入门:如何用自然语言分析大型数据集?
自然语言处理(NLP)是一项令人兴奋的前沿研究,Siri、Alexa和谷歌Home等产品都在努力完善自然语言处理方面的能力。为了使用NLP,我们必须了解这种处理方式的工作原理,我们可以用它来做哪些事情以及如何从原始数据到最终产品。
赵钰莹 · 2018-05-25 17:21 - 八步教你在笔记本电脑创建Hadoop本地实例!
要想进入大数据领域,Hadoop是一件非常重要的事情,它具有复杂的安装过程,大量的集群,数百台机器以及TB(或者PB)级别的数据等。但实际上,用户可以下载简单的JAR并在个人笔记本电脑上运行带HDFS的Hadoop以供练习,这对于想了解Hadoop的新手而言是个不错的方式。
赵钰莹 · 2018-05-25 17:21 - 如何利用散点图矩阵进行数据分析可视化?
当你得到一个很不错的干净数据集时,下一步就是探索性数据分析(Exploratory Data Analysis,EDA)。EDA 可以帮助发现数据想告诉我们什么,可用于寻找模式、关系或者异常来指导我们后续的分析。尽管在 EDA 中有很多种可以使用的方法,但是其中最有效的启动工具之一就是散点图矩阵(pairs plot,也叫做 scatterplot matrix)。散点图矩阵允许同时看到多个单独变量的分布和它们两两之间的关系。
赵钰莹 · 2018-05-25 13:59