产品
数字化转型步伐加快,软件定义整个世界,云计算与大数据、人工智能、5G等新一代信息技术互融互通……新华三把一切变化概括为“云智原生时代来临”。
关于数据治理,国际数据治理研究所(DGI)给出的定义是:“数据治理是一个通过一系列信息相关的过程来实现决策权和职责分工的系统,这些过程按照达成共识的模型来执行,该模型描述了谁(Who)能根据什么信息,


数据作为数字经济时代核心的生产要素,已经成为经济增长的动力引擎。近几年,随着国家相关数据安全法规的陆续出台,数据安全被提升到了一个新的高度,甚至上升到国家战略层面。大数据作为企业数据资产的主要载体,是



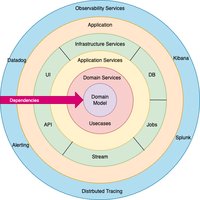
领域是一个知识的范畴。它指的是我们的软件所要模拟的业务知识。领域驱动设计的中心是领域模型,它对一个领域的流程和规则有着深刻的理解。洋葱架构实现了这一概念,并极大地改善了代码的品质,降低了复杂性,并且支
最初企业存储数据都在数仓中存储,但是随着数据量的增大,传统数据的方案在时效性上和数据维护上变得越来越困难。实时数仓架构应运而生。但具体方案落地上它有很多方案可选,那么面对不同的业务和应用场景我们到底应

近几年数据中台兴起,成为金融行业的话题之王,大数据平台被谈论得相对较少。随着云计算、AI等技术的兴起与大数据的融合加深,大数据平台已经站在了新的关口。

毋庸置疑,脑科学未来会是生命科学发展中重要的一个领域。随着更多人关注到这个领域,我们可以期待更多的人才、资金将会进入这个领域,在良好的政策支持下,推进脑科学领域的发展,为我们带来更多令人振奋的科技突

数据化、数字化、智能化,人类正在由物理世界向数字世界快速迁移,以数据作为新型生产要素的新商业环境正在崛起,如果非要用一句点睛之笔来总结,那应该是数据智能时代正在缔造新的经济帝国。

近日,Java官方团队正式发布Java 17。被称为史上最快,是因为OptaPlanner网站做了一项基准测试。通过比较JDK 17、JDK 16和JDK 11来告诉你答案。

低代码和无代码开发平台都致力于帮助专业和非专业开发人员高效创建应用,提高生产力。通过平台即服务(PaaS)的方式,这两种开发平台都削减了环境搭建以及基础设施维护的成本。但除此之外,它们几乎没有其他相同

千载夜郎,悠悠黔城,在数字经济时代焕发出新的光彩。正是基于把大数据先发优势转化为未来的发展胜势的全面布局,贵阳持续用好“中国数谷”这张名片,源源不断地在大数据引领创新驱动发展上实现新作为、取得新进展

众所周知,领域驱动设计(DDD)的概念出自Evic Evans的《领域驱动设计:软件核心复杂性应对之道》。它是指通过统一语言、业务抽象、领域划分和领域建模等一系列手段来控制软件复杂度的方法论。

数据作为第五大生产要素,已逐渐成为政府和企业决策的重要手段与依据。面对数据多样化、数据需求个性化、数据应用智能化的需求,以及在2B和2G行业中数据质量参差不齐、数据应用难以发挥价值、数据资产难以沉淀等
微信推广,WEIQ通过数据匹配红人粉丝与潜在客群的相似度,红人粉丝与潜在客群受众相似度越高,传播层级深所带来的长尾流量越多,以达到深度种草,沉淀长尾,构建品牌的私域流量。

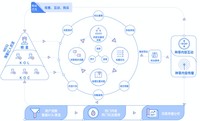
与此同时,WEIQ此番强势出圈,让中小商家看到全球最大的红人广告投放平台WEIQ是如何运作的,也展示了WEIQ用技术与能力为中小商家打造红人营销闭环,依托大数据模型,通过对WEIQ不断积累的大数据进行